(电脑)在ASCII后最常用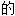 标准字符集。ASCII虽然仍是电脑运作基础。但是毕竟太少。跟不上电脑应用发展脚步。Unicode更强大。前面255个Unicode字符可以映射ASCII字符表。
标准字符集。ASCII虽然仍是电脑运作基础。但是毕竟太少。跟不上电脑应用发展脚步。Unicode更强大。前面255个Unicode字符可以映射ASCII字符表。
国际标准组织于1984年4月成立ISO/IEC JTC1/SC2/WG2工作组。针对各国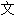 字、符号进行统一性编码。1991年美国跨国公司成立Unicode Consortium。并于1991年10月与WG2达成协议。采用同一编码字集。目前Unicode是采用16位编码体系。其字符集内容与ISO10646BMP(Basic Multilingual Plane)相同。Unicode于1992年6月通过DIS(Draf International Standard)。目前版本V2.0于1996公布。内容包含符号6811个。汉字20902个。韩
字、符号进行统一性编码。1991年美国跨国公司成立Unicode Consortium。并于1991年10月与WG2达成协议。采用同一编码字集。目前Unicode是采用16位编码体系。其字符集内容与ISO10646BMP(Basic Multilingual Plane)相同。Unicode于1992年6月通过DIS(Draf International Standard)。目前版本V2.0于1996公布。内容包含符号6811个。汉字20902个。韩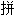
 11172个。造字区6400个。保留20249个。
11172个。造字区6400个。保留20249个。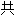 计65534个。
计65534个。
随着国际互联
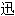 速发展。要求进行数据交换需求越来越大。不同编码体系越来越成为信息交换障碍。而且多种语言存档不断增多。单靠代码页已很难解决这些问题。于是UNICODE应运而生。
速发展。要求进行数据交换需求越来越大。不同编码体系越来越成为信息交换障碍。而且多种语言存档不断增多。单靠代码页已很难解决这些问题。于是UNICODE应运而生。
UNICODE有双重含义。首先UNICODE是对国际标准ISO/IEC10646编码一种称谓(ISO/IEC10646是一个国际标准。亦称大字符集。它是ISO于1993年颁布一项重要国际标准。其宗旨是全球所有种统一编码)。另外它又是由美国HP、Microsoft、IBM、Apple等大企业组成联盟集团名称。成立该集团宗旨就是要推进多种统一编码。
UNICODE同现在流行代码页最显著不同点在于:UNICODE是两字节全编码。对于ASCII字符它也使用两字节表示。代码页是通过高字节取值范围来确定是ASCII字符。还是汉字高字节。如果发生数据损坏。某处内容破坏。则会引起其后汉字混乱。UNICODE则一律使用两个字节表示一个字符。最明显好处是它简化了汉字处理过程。
UNICODE使用平面来描述编码空间。每个平面分为256行。256列。相对于两字节编码高低两个字节。
UNICODE第一个平面。称为Basic Multilingual Plane(基本多种平面)。简称BMP。由于BMP仅用两个字节表示。所以倍受青睐。
Unicode最初目标。是用1个16位编码来为超过65000字符提供映射。但这还不够。它不能覆盖全部历史上字。也不能解决传输问题(implantation head-ache's)。尤其在那些基于络应用中。因此。Unicode用一些基本保留字符制定了三套编码方式。它们分别是UTF-8,UTF-16和UTF-32。正如名字所示。在UTF-8中。字符是以8位序列来编码。用一个或几个字节来表示一个字符。这种方式最大好处。是UTF-8保留了ASCII字符编码做为它一部分。例如。在UTF-8和ASCII中。"A"编码都是0x41.UTF-16和UTF-32分别是Unicode16位和32位编码方式。考虑到最初目。通常说Unicode就是指UTF-16。
多年来。计算机普遍采用美国信息交换标准代码(American Standard Code for Information Interchange,简称ASCII码)来表示字符。这些字符可以是字母。数字。标点符号和控制符。用这种编码来表示英在内字符不成问题。但要表示其它语言字如。阿拉伯。中。日。维。哈...必须进行扩充。在1987年。Xerox Palo Alto研究中心Joe Becker和Lee Collins。以及Apple公司Mark Davis试图研究一种适用于多种处理字符编码。这种编码很快就得到了许多大公司支持。这些公司都派代表参加Unicode研究组。Unicode研究得到了较快进展。由于Unicode集团成员都是世界上主要系统及软件制造商。所以Unicode很快就成为事实上工业标准。
基于Unicode系统允许使用65000个不同字符。足以善盖世界所有语言所有字母。外加数千种符号。
其中。General Scripts区单独收录了19种语言字。包括ASCII,Latin1,Greek,Cyrillic,Armenian,Hedrew,Arabic,Devanagari,Bengali ,Gurmukhi,Gujarati,Oriya,Tamil,Telugu,Kannada,Malayalam,Thai,Lao,Tibetan,Georgian等语言字之外。还包括汉语。日语和朝鲜语中所有大量字符。
Unicode是一种定长2B多种字符集编码。它试图善盖现有有关国家和地区标准。包括GB2312,CNS11643,JIS 0208和KSC 5601等。Unicode可以表示混合字资料。也可以保证以前ISO 10646。
凡顺提示:Win98以前操作系统不支持Unicode。
标准字符集。ASCII虽然仍是电脑运作基础。但是毕竟太少。跟不上电脑应用发展脚步。Unicode更强大。前面255个Unicode字符可以映射ASCII字符表。国际标准组织于1984年4月成立ISO/IEC JTC1/SC2/WG2工作组。针对各国
字、符号进行统一性编码。1991年美国跨国公司成立Unicode Consortium。并于1991年10月与WG2达成协议。采用同一编码字集。目前Unicode是采用16位编码体系。其字符集内容与ISO10646BMP(Basic Multilingual Plane)相同。Unicode于1992年6月通过DIS(Draf International Standard)。目前版本V2.0于1996公布。内容包含符号6811个。汉字20902个。韩11172个。造字区6400个。保留20249个。计65534个。随着国际互联
速发展。要求进行数据交换需求越来越大。不同编码体系越来越成为信息交换障碍。而且多种语言存档不断增多。单靠代码页已很难解决这些问题。于是UNICODE应运而生。UNICODE有双重含义。首先UNICODE是对国际标准ISO/IEC10646编码
一种称谓(ISO/IEC10646是一个国际标准。亦称大字符集。它是ISO于1993年颁布一项重要国际标准。其宗旨是全球所有种统一编码)。另外它又是由美国HP、Microsoft、IBM、Apple等大企业组成联盟集团名称。成立该集团宗旨就是要推进多种统一编码。UNICODE同现在流行
代码页最显著不同点在于:UNICODE是两字节全编码。对于ASCII字符它也使用两字节表示。代码页是通过高字节取值范围来确定是ASCII字符。还是汉字高字节。如果发生数据损坏。某处内容破坏。则会引起其后汉字混乱。UNICODE则一律使用两个字节表示一个字符。最明显好处是它简化了汉字处理过程。UNICODE使用平面来描述编码空间。每个平面分为256行。256列。相对于两字节编码
高低两个字节。UNICODE
第一个平面。称为Basic Multilingual Plane(基本多种平面)。简称BMP。由于BMP仅用两个字节表示。所以倍受青睐。Unicode
最初目标。是用1个16位编码来为超过65000字符提供映射。但这还不够。它不能覆盖全部历史上字。也不能解决传输问题(implantation head-ache's)。尤其在那些基于络应用中。因此。Unicode用一些基本保留字符制定了三套编码方式。它们分别是UTF-8,UTF-16和UTF-32。正如名字所示。在UTF-8中。字符是以8位序列来编码。用一个或几个字节来表示一个字符。这种方式最大好处。是UTF-8保留了ASCII字符编码做为它一部分。例如。在UTF-8和ASCII中。"A"编码都是0x41.UTF-16和UTF-32分别是Unicode16位和32位编码方式。考虑到最初目。通常说Unicode就是指UTF-16。多年来。计算机普遍采用美国信息交换标准代码(American Standard Code for Information Interchange,简称ASCII码)来表示字符。这些字符可以是字母。数字。标点符号和控制符。用这种编码来表示英
在内字符不成问题。但要表示其它语言字如。阿拉伯。中。日。维。哈...必须进行扩充。在1987年。Xerox Palo Alto研究中心Joe Becker和Lee Collins。以及Apple公司Mark Davis试图研究一种适用于多种处理字符编码。这种编码很快就得到了许多大公司支持。这些公司都派代表参加Unicode研究组。Unicode研究得到了较快进展。由于Unicode集团成员都是世界上主要系统及软件制造商。所以Unicode很快就成为事实上工业标准。基于Unicode
系统允许使用65000个不同字符。足以善盖世界所有语言所有字母。外加数千种符号。其中。General Scripts区单独收录了19种语言
字。包括ASCII,Latin1,Greek,Cyrillic,Armenian,Hedrew,Arabic,Devanagari,Bengali ,Gurmukhi,Gujarati,Oriya,Tamil,Telugu,Kannada,Malayalam,Thai,Lao,Tibetan,Georgian等语言字之外。还包括汉语。日语和朝鲜语中所有大量字符。Unicode是一种定长
2B多种字符集编码。它试图善盖现有有关国家和地区标准。包括GB2312,CNS11643,JIS 0208和KSC 5601等。Unicode可以表示混合字资料。也可以保证以前ISO 10646。凡顺提示:Win98以前
操作系统不支持Unicode。用户正在搜索
Hauptrotorachse, Hauptrückführung, Hauptrumpf, Hauptsache, hauptsächlich, Hauptsaison, Hauptsammelleitung, Hauptsammellinse, Hauptsammelschiene, Hauptsammler,
相似单词
Uni, UNI(user network interface), uniaxial, Unicafé, UNICEF, Unicode, UNICOM, unidirektional, unidirektionaler Strom, unido,